Mickey Leland Energy Fellowship (National Energy Technolgy Lab at the Department of Energy): Topic Modeling of Energy Storage Literature
Description:
Storing energy from intermittent renewables, such as wind and solar, is one of the most pressing challenges we face for enabling a sustainable civilization.
To efficiently allocate resources, researchers and administrators need a high level understanding of the field of energy-storage.
During my summer with the Department of Energy, I used natural language processing techniques to extract insights from tens of thousands of scientific abstracts
relating to energy-storage, and I created interactive visualizations for exploring my results.
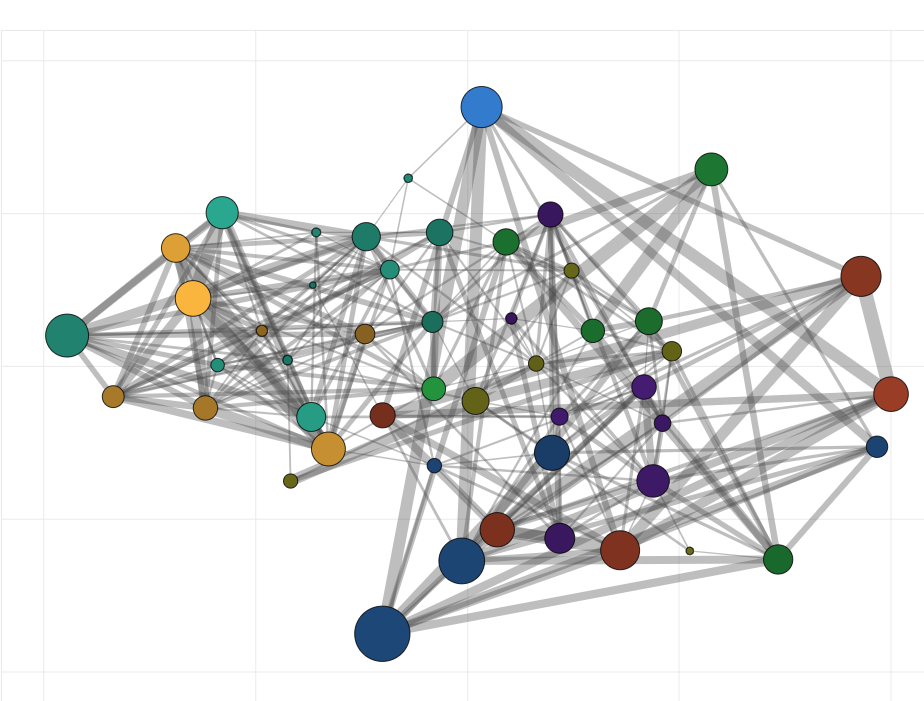
For my first visualization, I used LDA to do topic modeling of the energy storage literature and created an interactive graph that allows you to explore topics and their intersections.
For the second visualization, I used Word2Vec to create word vectors from prevelant terms in the data.
I then used tSNE to project these vectors to a 2D plane for interactive visualization. This tool also allows users to do vector math with the word vectors (more info on the website).
Interesting results or findings:
We found that the model generated topics that were sensible and specific, and that the community detection made groupings that were interpretable and interesting.
Some topics were technology-focused such as topic 49 which is centered around electric vehicles.
Other concepts were more abstract such as topic 23 which had more to do with grid optimization and energy management.
The connections between topics were also sensible. The connection between topics 49 and 23 for instance involves vehicle to grid and grid to vehicle research.
The Word2Vec visualization was a little bit less intuitive, but the similar words all seemed very reasonable.
For example, the closest words to "solar" are "sun, photovolta, sunlight, parabol_trough, pvt, csp, plant, flat_plate, geotherm, and panel".
The vector math took some time to build intuition for, but also produced meaningful results.
For instance, COST - EFFICI + CYCL = LONG_TERM which makes sense because the efficiency of a battery is to the cost as the cyclability is to the lifetime.
More specific results can be found on the website.
Challenges:
The biggest challenge of this project was familiarizing myself with the number of different libraries and tools involved.
I had previously never worked with Gensim, Bokeh, or Javascript, so quickly familiarizing myself with these tools enough to complete this project
in ten weeks was a large and sometimes very frusterating task. Additionally, the data cleaning process is imperfect. Not all punctuation was removed,
and there are still some non-English papers.
Skills:
Latent Dirichlet Allocation (LDA), Word2Vec, Louvain Community Detection, tSNE, Python, Bokeh, Javascript, html, css, Data Visualization, Visual Studios, GitHub
Code:
Project Website:
Energy Storage Website (serves as writeup as well)